Grounding LLM with Real-time Data
How to ground LLMs with real-time data using web search tools and structured outputs. Compare different approaches including search APIs, native LLM tools, and MCP integration.
Grounding LLMs with Real-time Data
- Grounding LLMs with Real-time Data
- Provider Comparison
- Conclusion
When you build an AI agent or large language model (LLM) workflow, one major pain point is stale or hallucinated output.
For example, imagine a travel operations manager trying to keep attendees updated on airport delays, flight cancellations, or sudden event schedule changes. Without live data, the team spends time manually searching multiple sites, risking missed alerts.
Here’s the thing: if you want your AI workflow to be trustworthy and actionable, you need grounding — anchoring the output in live web search results or other external data.
Grounding means your model doesn’t just rely on internal knowledge; it taps into up-to-date external sources, typically via search tools.
A simple example : you ask “What’s the latest regulation for AI models in the EU?” If the LLM only uses its training cut-off (say mid-2024), it might be wrong. If instead it uses a search tool to fetch the latest web articles or a reliable database of regulation and then incorporates them into its reasoning — much better.
My Checklist for AI Teams
If I were advising a team building real-time workflows (like travel alerts, events, or logistics), here’s what I’d have them check before implementing grounding:
- Do we have queries where live data matters and could change suddenly?
- Can we afford the extra latency and cost of live search?
- Are we capturing metadata (queries, sources, timestamps) for observability?
- Do we monitor how often grounding is used and how successful it is?
- Are we prepared for user trust / audit questions — which source, when, and how up-to-date?
Case Study (AI Workflow Example – Travel & Events)
Problem:
A travel operations manager for a global conference platform wants to keep attendees informed in real time about airport delays, cancellations, or sudden event venue changes. Currently, the team manually searches multiple airline and local news sites to verify information — slow and error-prone.
AI Assistant with Grounding:
- Triggers a web search for queries like:
“London Heathrow flight delays today Oct 25 2025” or
“FIFA fan fest schedule updates October 2025” - Fetches up-to-the-minute news articles, tweets from official sources, and announcements
- Injects context into the LLM prompt
- Generates concise updates:
“According to Heathrow Airport (URL), flights from Terminal 5 are delayed due to technical issues. The FIFA Fan Fest schedule has moved the 5 PM match preview to the east plaza.”
- Logs metadata: query, URLs, fetch timestamp, source credibility
Outcome:
- Operations team and attendees get instant, actionable alerts
- Reduces manual search overhead and error risk
- All alerts are traceable for reporting or audit purposes
Takeaway:
Grounding turns the AI from a “best guess” assistant into a reliable real-time workflow tool, automatically keeping teams up to date in situations where schedules or conditions change suddenly.
Now, let’s get practical
Let’s look at how to implement grounding with real-time web search and structured outputs.
Without grounding in search
resp = client.chat.completions.create( model="gpt-5", messages=[ {"role": "system", "content": "You are a helpful assistant."}, { "role": "user", "content": "What was the latest Indian Premier League match and who won?", }, ], )
RESPONSE: I don’t have live access to today’s results. The most recent IPL match I have on record (up to Oct 2024) is the IPL 2024 Final on 26 May 2024, where Kolkata Knight Riders beat Sunrisers Hyderabad by 8 wickets. If you want the latest match result right now, please check: - Official: iplt20.com/matches/results - ESPNcricinfo: espncricinfo.com/series/ipl-2025-xxxxx/match-schedule-fixtures-and-results
Here are the knowledge cutoff dates for major models:
| Model | Knowledge Cutoff |
|---|---|
| GPT-4.1 | June 2024 |
| o4-mini | June 2024 |
| GPT-5 (reports vary) | Sept–Oct 2024 |
| Claude 3.5 Sonnet | April 2024 |
| Claude 3.7 Sonnet | Oct–Nov 2024 |
| Claude 4 (Opus/Sonnet) | Jan–Mar 2025 |
| Gemini 2.5 (Pro/Flash) | Jan 2025 |
| DeepSeek-V3 | July–Dec 2024 |
| QwQ-32B | Nov 28, 2024 |
Why Structured Outputs Are Critical for Search Grounding
When you ground an LLM with web search results, the output can be messy — dates, names, or numbers might get mixed up across multiple sources, and the LLM might phrase things differently each time. This makes it hard to use the results in a real workflow or feed them into downstream tools.
Structured outputs solve this problem by enforcing a consistent, machine-readable format. They provide:
- Reliability: Each answer can be parsed automatically without fragile heuristics.
- Consistency: Multiple queries follow the same format, making dashboards and analytics accurate.
- Traceability: Each piece of data links back to its source, timestamp, and query.
- Safer automation: Downstream AI agents or business processes can consume the data without introducing errors or hallucinations.
Example (Unstructured vs Structured)
Unstructured output from LLM:
“According to the news, Company X launched Product Y yesterday, and analysts are optimistic about its growth.”
Structured output:
{ "company": "Company X", "product": "Product Y", "launch_date": "2025-10-24", "source": "https://news.example.com/article123", "analyst_sentiment": "positive" }
With this structure, your system can automatically:
- Update dashboards
- Trigger notifications for relevant teams
- Feed data into other AI agents or reporting pipelines
Structured outputs are not just a “nice-to-have.” They turn messy web data into actionable intelligence, which is essential for any real-world AI workflow that relies on live data.
Implementation
Some use cases demand live data — like news verification, travel updates, or event alerts.
There are three main ways to add real-time search grounding:
-
Search API + Structured Output (Recommended)
Use providers like Exa, Brave, or Google Search API, then format the output with Instructor or BAML. -
Native LLM Tools
Use the built-in search tools from providers like OpenAI, Anthropic, or Gemini. -
MCP-based Search Integration
Best for local development or if your pipeline already runs on MCP servers.
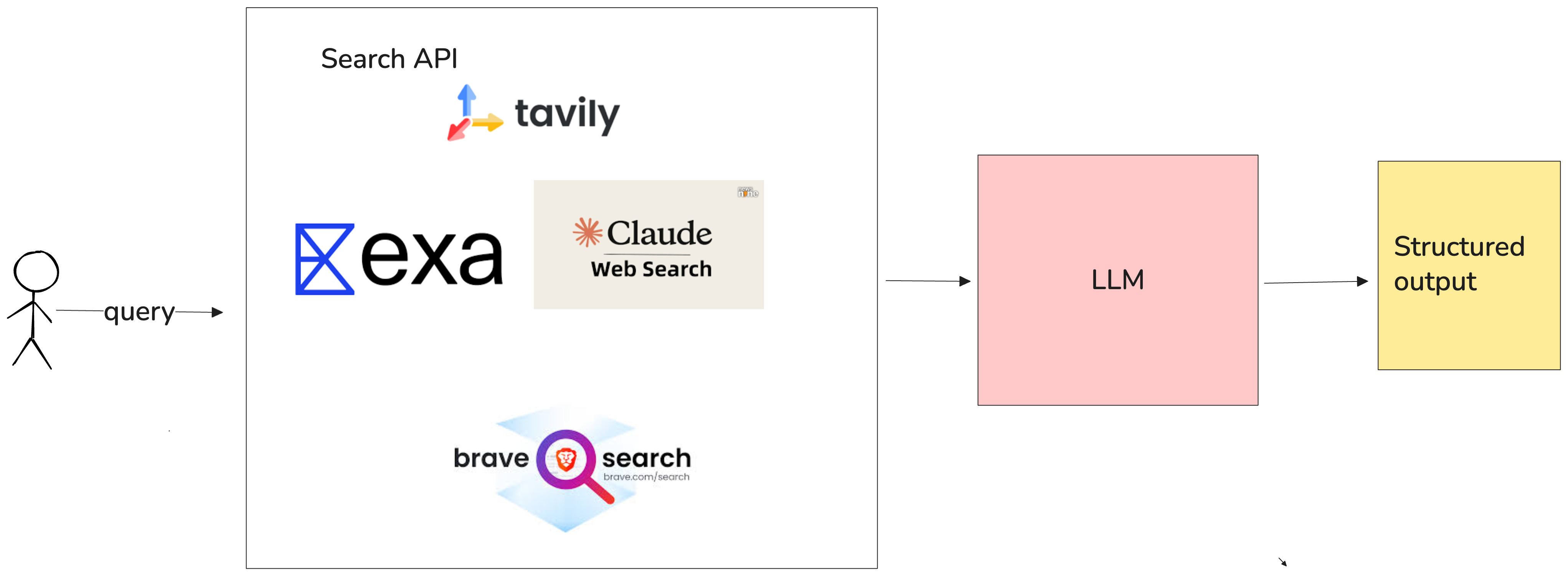
1. Search API + Structured Output
This gives you the most control to pick and choose LLM providers, search engine and other factors to give the best result.
def execute_web_search(query): exa = Exa(api_key=api_key) search_params = { "query": query, "num_results": 5, "text": True, "type": "auto", } search_response = exa.search_and_contents(**search_params)
Filter and summarize results with structured output:
// websearch.baml class CleanSummary { answer string links string[] } function SummarizeAndClean(results: SearchResults[]) -> CleanSummary[] { client "openai/gpt-4.1" prompt #" Summarize these search results into clean, concise summaries: - Remove any profanity - Keep key details - Include relevant links - Use the latest info if conflicting {{ ctx.output_format }} "# }
2. Use Native Tools from LLM Providers
This is the fastest way to get started.
Using OpenAI client:
from openai import OpenAI client = OpenAI() response = client.responses.create( model="gpt-5", tools=[{"type": "web_search"}], input="What was a positive news story from today?" ) print(response.output_text)
Using Gemini models:
response = client.models.generate_content( model=MODEL_ID, contents="What was the latest Indian Premier League match and who won?", config={"tools": [{"google_search": {}}]}, ) # print the response display(Markdown(f"**Response**:\n {response.text}")) # print the search details print(f"Search Query: {response.candidates[0].grounding_metadata.web_search_queries}") # urls used for grounding print(f"Search Pages: {', '.join([site.web.title for site in response.candidates[0].grounding_metadata.grounding_chunks])}") display(HTML(response.candidates[0].grounding_metadata.search_entry_point.rendered_content))

The new google maps integration with Gemini API allows you ground results in maps which enables pretty interesting queries like
Do any cafes around here do a good flat white? I will walk up to 20 minutes away
Native tool + Structured outputs
Combining structured outputs with native tools gives you more control over data format and consistency.
// websearch.baml client<llm> WebSearchClient { provider "openai-responses" options { api_key env.OPENAI_API_KEY model "gpt-5" tools [{ type "web_search" }] } function SearchNews(query: string) -> WebResults { client WebSearchClient prompt #" Search for and summarize {{ query }}. Only give results for 2025 pointwise. Limit the search results to 3. {{ctx.output_format }} "# } // query "what are the biggest conferences on AI Engineering and what do they focus on ?"
3. MCP for Search Integration
This approach makes sense if you are already using MCP in your AI pipeline and websearch would another server. If you are using claude desktop or IDE that supports MCP , it's pretty easy to add websearch MCP server .
Create a custom client to connect to EXA MCP
from fastmcp import FastMCP mcp = FastMCP( "Exa MCP Client", url=EXA_MCP_URL, headers={"Authorization": f"Bearer {EXA_API_KEY}"} ) async def main(): tools = await mcp.list_tools() search_response = await mcp.call_tool( "exa_search", {"query": "artificial intelligence latest developments", "num_results": 5} ) asyncio.run(main())
Provider Comparison
| Provider | Index Type | Typical Cost | Strengths | Best Fit |
|---|---|---|---|---|
| Brave Search API | Independent | ~$0.005 | Fresh index, high QPS | Broad, low-cost grounding |
| Google Programmable Search | ~$0.005 | Huge corpus | Google-specific retrieval | |
| Perplexity API | Aggregated + LLM ranking | ~$0.005 | Hybrid ranking | Default SERP-style retrieval |
| Tavily | Meta-search + extract | 1–2 credits | LLM-focused | Agentic RAG |
| Exa | In-house + content fetch | ~$0.005 | Fine-grained control | Summarization & analysis |
| Anthropic Web Search | Native tool | ~$0.01 + tokens | Governance, citations | LLM-native agents |
| Kagi API | Curated | ~$0.025 | Privacy, ad-free | Premium user experiences |
-
Fact lookups at scale :Use Brave Base or Google JSON for lowest cost per query, high QPS, and straightforward SERP parsing.
-
Agentic RAG - Tavily and EXA if you want summaries and keep tight control over the output structure.
-
Fully LLM-native research tasks - Use Anthropic Web Search for tool-based queries with automatic citations, multi-step searches, and domain allow/block lists. This is easiest to get started.
-
High-fidelity, privacy-focused consumer search in product: Use Kagi API when curated ranking and ad-free results matter more than marginal per-query cost; good for premium user experiences.
Conclusion
Based on your use case — whether you’re researching, verifying, or reasoning — choose the grounding method that fits best.
But for all use cases, structured outputs help you experiment faster, track retrieval performance, and make your AI pipeline production-ready.
Try out the examples here:
github.com/sandipan1/baml-agents