PII Extraction for RAG: Building Secure Document Pipelines
Learn how to build secure RAG pipelines with PII extraction and scrubbing. Protect sensitive information while improving retrieval quality using BAML for structured validation.
PII Extraction for RAG
Introduction
Retrieval-Augmented Generation (RAG) is quickly becoming the most common way enterprises use large language models. By combining real-world documents with LLMs, companies can answer questions, automate workflows, and generate insights on internal data.
But here’s the thing: not all data should be freely accessible. Some documents contain sensitive information like personally identifiable information (PII), internal reports, or confidential records. If RAG pipelines aren’t designed carefully, the wrong user could get access to the wrong information — creating serious security and compliance risks.
Why PII Extraction is Neccessary
When you build Retrieval-Augmented Generation (RAG) systems for enterprises, most real-world documents contain personally identifiable information (PII) — names, emails, phone numbers, social security numbers, etc.
If this data goes into your embeddings or indexes directly, you risk:
- Leaking private information
- Breaking compliance (GDPR, CCPA)
- Producing biased or irrelevant model outputs
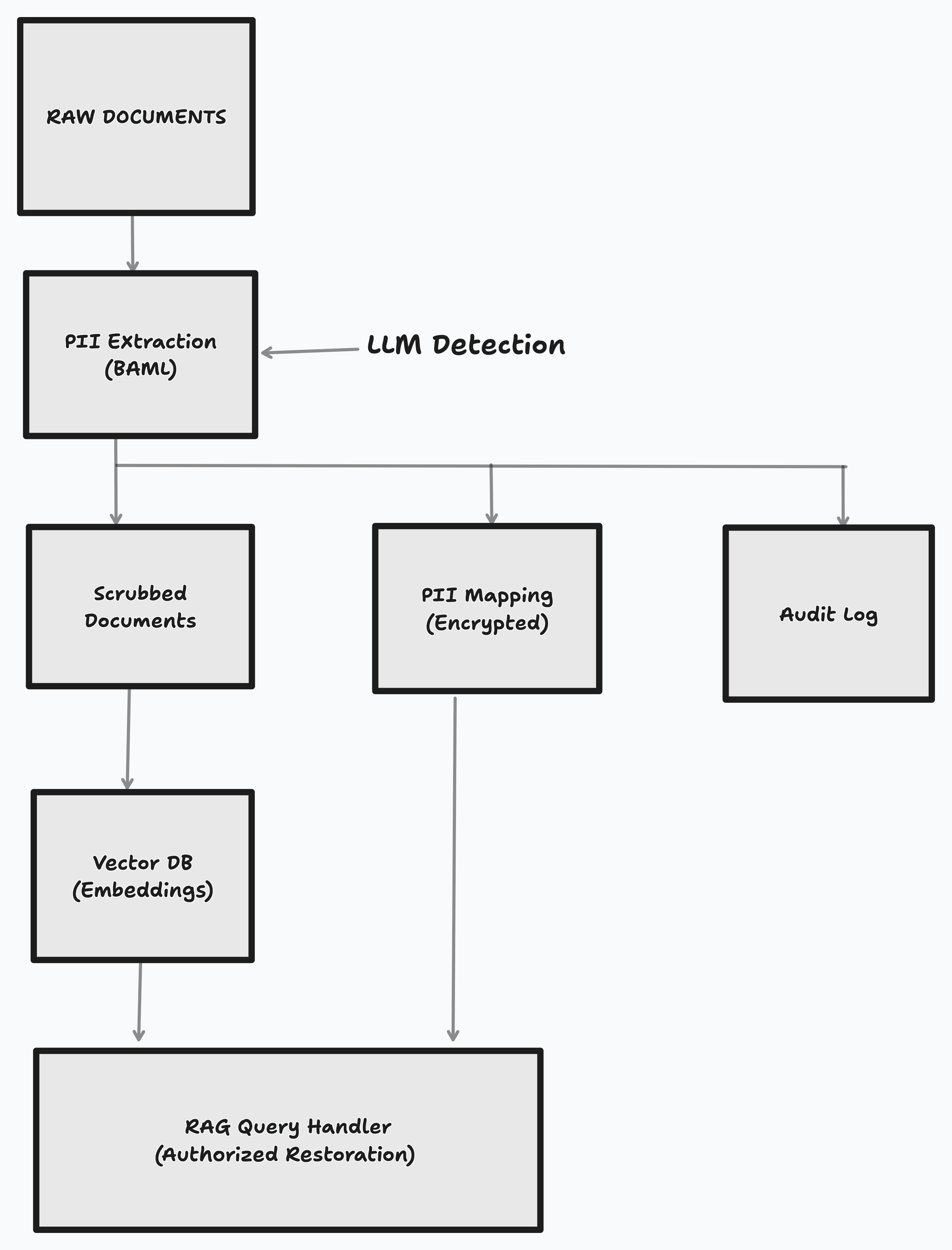
The solution is a clean PII extraction and scrubbing pipeline in the ingestion step. It strips sensitive data before ingestion, keeps a secure mapping, and restores it when needed.
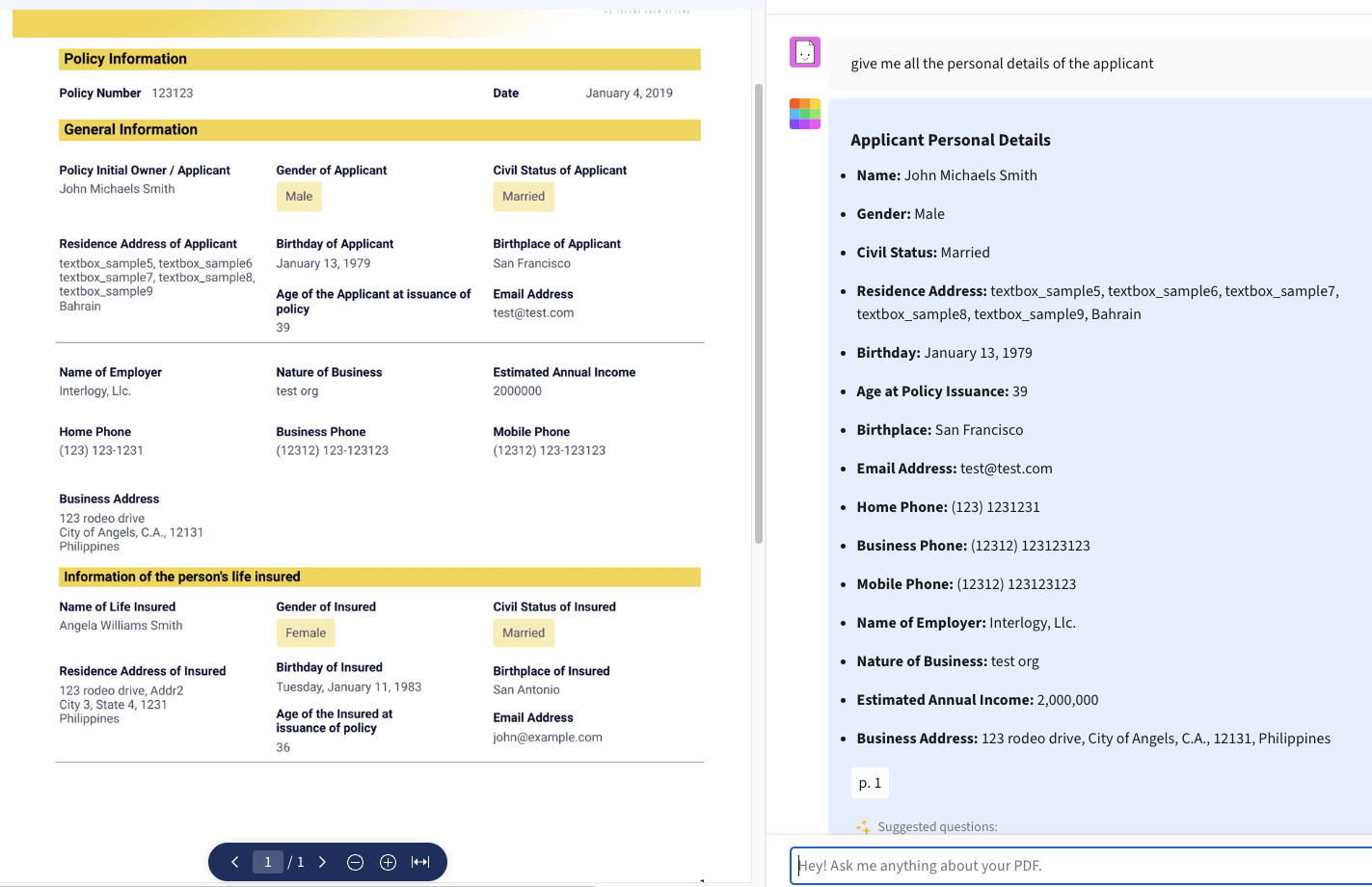
You wouldn't want user to query like this with sensitive documents
How It Works
- Documents pass through PII extraction before indexing.
- Sensitive fields are replaced with placeholders.
- This not only protects privacy, but also reduces bias in embeddings. For example, names, locations, or other demographic info can unintentionally skew retrieval.
- The mapping is stored securely and linked to the document ID.
- The scrubbed document is chunked, embedded, and indexed.
- Working with scrubbed documents can improve recall, because embeddings focus on content rather than sensitive identifiers.
- During retrieval, the model works on safe text, and restoration happens only for authorized users.
Execution (BAML )
Extract PII with LLM
Let's look at the Data Schema and the extraction function
PIIData : Class representing single PII with its type and value
PIIExtraction : Holds array of PII data items with sensitive data flag
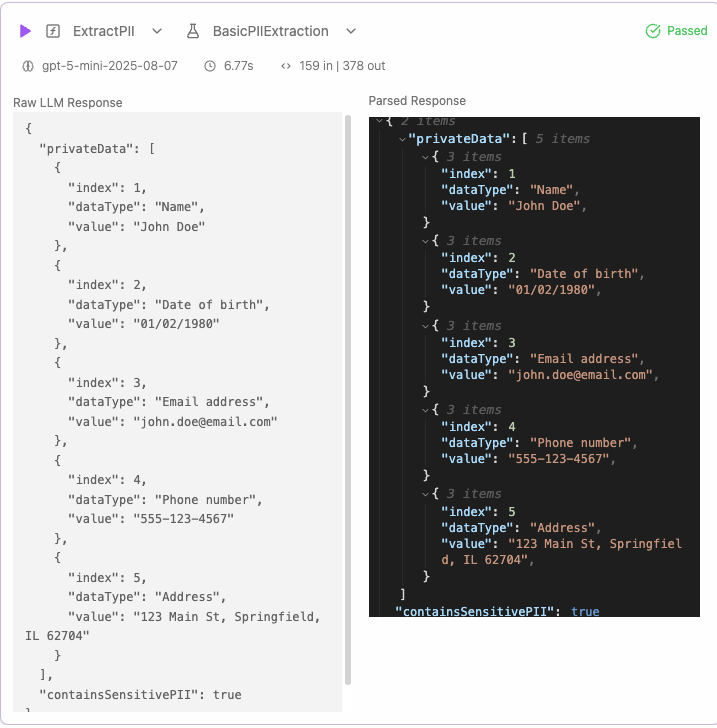
//pii.baml class PIIData { index int dataType string value string } class PIIExtraction { privateData PIIData[] containsSensitivePII bool @description("E.g. SSN") } function ExtractPII(document: string) -> PIIExtraction { client "openai/gpt-5-mini" prompt #" Extract all personally identifiable information (PII) from the given document. Look for items like: - Names - Email addresses - Phone numbers - Addresses - Social security numbers - Dates of birth - Any other personal data {{ ctx.output_format }} {{ _.role("user") }} {{ document }} "# } test BasicPIIExtraction { functions [ExtractPII] args { document #" John Doe was born on 01/02/1980. His email is john.doe@email.com and phone is 555-123-4567. He lives at 123 Main St, Springfield, IL 62704. "# } }
RESPONSE :
Scrub the Data
Replace the PII information with respective placeholders using direct string replacement.
Original Document :
John Smith works at Tech Corp. You can reach him at john.smith@techcorp.com or call 555-0123 during business hours. His employee ID is TC-12345.
Scrubbed Document
[NAME_1] works at Tech Corp. You can reach him at [EMAIL_2] or call [PHONE_3] during business hours. His employee ID is [EMPLOYEE ID_4].
Using scrubbed
Mapping Preservation
Map the PII data to the respective place holder
{ "[NAME_1]": "John Smith", "[EMAIL_2]": "john.smith@techcorp.com", "[PHONE_3]": "555-0123", "[EMPLOYEE ID_4]": "TC-12345" }
You can store the mapping in an encrypted database (e.g., PostgreSQL with pgcrypto) or secure key-value store (e.g., AWS Secret Manager). If you already have access control for the documents, you should extend that to the mapping so only authorized users who already have access to the document can decrypt/view the mapping.
Restoring documents
Allow partial or full restoration of the original text using the mapping when it is needed in the RAG application.
Restored Document:
John Smith works at Tech Corp. You can reach him at john.smith@techcorp.com or call 555-0123 during business hours. His employee ID is TC-12345.
Enhanced Security : Self hosted LLM
For organization handling sensitive data, using cloud hosted extenal LLMs like OpenAI GPT might not be suitable suitable due to data privacy concerns.
You can also mix models for the RAG pipeline i.e use local models for PII extraction step and hosted LLM for the rest
Simple define your local model client in
//you've need to install ollama with llama:3.1. // ollama pull llama:3.1 // ollama run llama:3.1 client<llm> SecureLocalLLM { provider "openai-generic" options { base_url "http://localhost:11434/v1" model "llama3.1:latest" temperature 0 default_role "user" } } // the rest is same as above
Traditional vs This Approach
Traditional Approach
Most traditional pipelines handle PII as a separate compliance step, using one of these methods:
Rule Based Approach : Use regular expressions or patterns to find things like phone numbers, emails, or IDs.
Example regex: \d{3}-\d{2}-\d{4} for social security numbers.
Problem: They fail with unstructured or context-heavy data.
Call HR for more details about John's compensation.
There’s no phone number or email, but “John’s compensation” is still sensitive
Named Entity Recognition (NER): Models trained to tag entities such as PERSON, LOCATION, or ORGANIZATION.
Works better on natural text, but misses subtle or domain-specific identifiers.
False positive : We are analyzing Apple’s quarterly results.
Apple here is a company, not a person, but NER models sometimes misclassify it.
Custom PII :
Customer ID: CUS-99821 Internal Ticket: SUP-1123
NER models rarely recognize IDs like these as PII because they’re not human names or addresses.
Manual redaction:
Human review to ensure compliance.
Accurate but slow, expensive, and impossible to scale for large document sets.
This Approach
LLM based PII extraction embeds privacy directly into the RAG ingestion pipeline rather than as a bolt-on process.
Contextual awareness:
The LLM can reason about why something is sensitive — not just what it looks like. For e.g
Our CFO’s assistant said the payment for Project Orion will be delayed.
Regex and NER won’t flag this, but an LLM can infer that “CFO’s assistant” and “Project Orion” represent internal-sensitive context.
Invariant to document types:
Can dynamically adapt to new document types or formats.
For e.g
In insurance claim document, it can identify “Policy ID: HDFC-98374” as sensitive even though “Policy ID” isn’t a standard NER tag.
or
In a multilingual customer chat, it can handle text like “Mi número es ९८७६५४३२१०, please call me tomorrow.”
This adaptability means the system stays robust as your data sources evolve — which is critical in enterprise RAG setups where new document formats show up constantly.
Final Thoughts
PII extraction isn’t just a compliance step — it’s part of building trustworthy AI systems.
Scrubbing sensitive information before ingestion has additional benefits beyond privacy:
- Reduces bias in retrieval, since demographic or personal identifiers don’t influence embeddings.
- Improves recall, because the RAG system focuses on the core content rather than extraneous PII.
It protects users, secures pipelines, and allows RAG systems to operate in regulated environments without leaking private information.
Check out the full example in https://github.com/sandipan1/baml-agents