Event-Driven Architecture for AI Agents - Solving Real Production Patterns
A deep dive into building production-ready AI agents using event-driven architecture to solve message queuing, interrupts, function calls, and background tasks
- The Patterns We Need to Solve
- Why Traditional Approaches Fail
- Architecting the Event-Driven System
- How Components Work Together
- Key Architectural Decisions Explained
- Production Considerations
- Conclusion
- Questions? Your Use Cases?
The Patterns We Need to Solve
If you are building for a good user experience with AI agents in production, you hit a few common patterns.Many of these patterns are already present in coding agnets claude code, cursor but these can be adapted in multiple domains. Let me show you what breaks with traditional architectures.
This is no simple way to handle these currently with any Agent Frameworks without getting burried deep into unknown abstractions.My goal is to simplify these patterns and come up with an architecture that solves for this.
Pattern 1: Streaming Responses (Real-Time Chunks)
Without streaming (broken experience):
User: "Explain how neural networks work"
↓
[Complete silence for 15 seconds]
↓
[Entire response appears at once]
AI: "Neural networks are computational models inspired by biological... [500 words]"
Problem: User waited 15 seconds staring at blank screen
With streaming (good experience):
User: "Explain how neural networks work"
↓
[Immediately, words appear as AI generates them]
AI: "Neural"
AI: " networks are"
AI: " computational models"
AI: " inspired by biological"
AI: " neurons..."
[Response builds character-by-character in real-time]
Result: User sees progress immediately, knows system is working
What we need:
- Start showing response immediately (within 1 second)
- Stream text chunks as they're generated
- User sees AI "thinking out loud" in real-time
- Like ChatGPT - no waiting for complete response
What breaks with synchronous buffering: The system buffers the entire LLM response until the HTTP request completes. The user sees nothing until the 15th second, creating a perceived latency that feels broken.
Pattern 2: Message Queuing
User: "Analyze our Q4 sales data"
AI: [Processing... takes 15 seconds]
User: "Actually, just show top 3 regions" [sent at 5 seconds]
AI: [Still processing first request]
What should happen:
↓
AI: [Finishes first analysis]
AI: [Automatically processes second request]
AI: [Returns top 3 regions]
User gets both answers without repeating themselves.
What breaks with blocking sequential loops: The system's control loop is blocked awaiting the first response (e.g., completion = await llm.run()). The second message is either not allowed to be send or arrives while the system is deaf to input, causing it to be dropped or not allowed.
Pattern 3: Interrupt Handling
User: "Explain quantum physics in detail"
AI: "Quantum physics is the study of matter at atomic scale..."
AI: "Let me explain wave-particle duality..."
AI: "Now, quantum entanglement is..." [going on for 5 minutes]
User: [Realizes this is too detailed]
User: [Clicks STOP]
What should happen:
↓
AI: [Stops immediately]
AI: Ready for new input
User: "Just give me 3 key points"
AI: [Processes new request]
What breaks with atomic execution: The chat.completions.create function captures the thread and runs to completion. Without an async event loop checking for signals, there is no way to inject a "stop" command into the running process.
Pattern 4: Function Calls with Human Approval
User: "Get our Q4 revenue from the database"
↓
AI: "I'll query the database for you"
AI: [Wants to run: SELECT revenue FROM sales WHERE quarter='Q4']
↓
[Approval modal appears]
"AI wants to run SQL query. Approve?"
↓
User: [Reviews query, clicks Approve]
↓
AI: [Executes query]
AI: "Q4 revenue was $2.5M"
What breaks with direct tool execution: Typical tool use patterns execute tools immediately upon selection. There is no intermediate state to pause execution and await a separate "approval" event from the client.
Pattern 5: Background Tasks with Notifications
User: "Analyze 5 years of sales data and generate trends report"
↓
AI: "This will take about 20 minutes. I'll notify you when done."
AI: [Starts background task]
↓
User: [Closes browser, goes to meeting]
↓
[20 minutes later]
AI: [Task completes]
↓
Notification Service:
• Checks if user is online → NO
• Sends email: "Your analysis is ready! [View Results]"
↓
User: [Returns, clicks link]
User: [Sees completed analysis]
What we need:
- Start long-running task without blocking
- User can disconnect and reconnect
- Notify via browser (if online) or email (if offline)
- Retrieve results later
What breaks with request-scoped lifecycle: The task runs within the HTTP request handler. If the user closes the tab, the socket closes, the web server terminates the request context, and the partially-complete task is killed.
Pattern 6: Repeatable Workflows (Slash Commands)
The scenario: Developer needs to run the same multi-step workflow repeatedly.
Developer: "/pr-review"
↓
System executes pre-defined workflow:
1. Get git diff of current branch
2. Send to AI: "Review this code for bugs and style issues"
3. AI streams review comments
4. Format results with line numbers
5. Show in UI with action buttons
↓
Result: PR review in 10 seconds (vs 5 minutes manually)
Developer: "/add-ticket Priority: High"
↓
System executes:
1. Extract context from current conversation
2. AI generates ticket description
3. Show approval modal with Jira ticket preview
4. On approve: Create ticket via Jira API
5. Return ticket link
↓
Result: Ticket created without leaving the chat
What we need:
- Define custom workflows (user or system-defined)
- Trigger with simple commands (
/workflow-name) - Workflows can call LLM multiple times
- Workflows can execute tools (git, API calls, database)
- Stream progress updates for each step
- Can be interrupted mid-workflow
What breaks with manual conversational loops:
- No Persistence: Complex chains of thought are ephemeral, lost once the chat scrolls up.
- No Determinism: You can't guarantee the AI will follow the exact same 5 steps next time you ask.
- Manual Toil: The user acts as the "glue" code, manually copy-pasting outputs from one step to the next.
Real-world workflows:
/pr-review- Code review with actionable suggestions/debug-error- Analyze stack trace, search codebase, suggest fix/refactor-function- Analyze function, propose improvements, apply changes/generate-tests- Write tests for selected code/update-docs- Update documentation based on code changes
Why Traditional Approaches Fail
In my last blog post Building an AI Agent Framework, I explained why HICA (my previous framework) couldn't handle these patterns:
- No streaming - 15 seconds of silence, then entire response appears at once
- No way to interrupt mid-operation - once it starts, it runs until done
- If you send a message while agent is busy, that message just disappears
- Can't intercept and approve actions before execution
The root cause? Sequential loop architecture.
HICA's agent_loop() processes one thing at a time in a blocking sequence:
while not done:
tool = select_tool() # Wait for LLM
params = fill_parameters() # Wait for LLM
result = execute_tool() # Wait for execution
# User sends message here? LOST - loop is blocked
When the loop is waiting for the LLM (10 seconds), it can't:
- Accept new user messages (they vanish)
- Send progress updates to UI (frozen screen)
- Check for interrupt signals (unstoppable)
- Queue messages for later (no queuing mechanism)
We need a different architecture.
Architecting the Event-Driven System
Let's build this step by step, component by component.

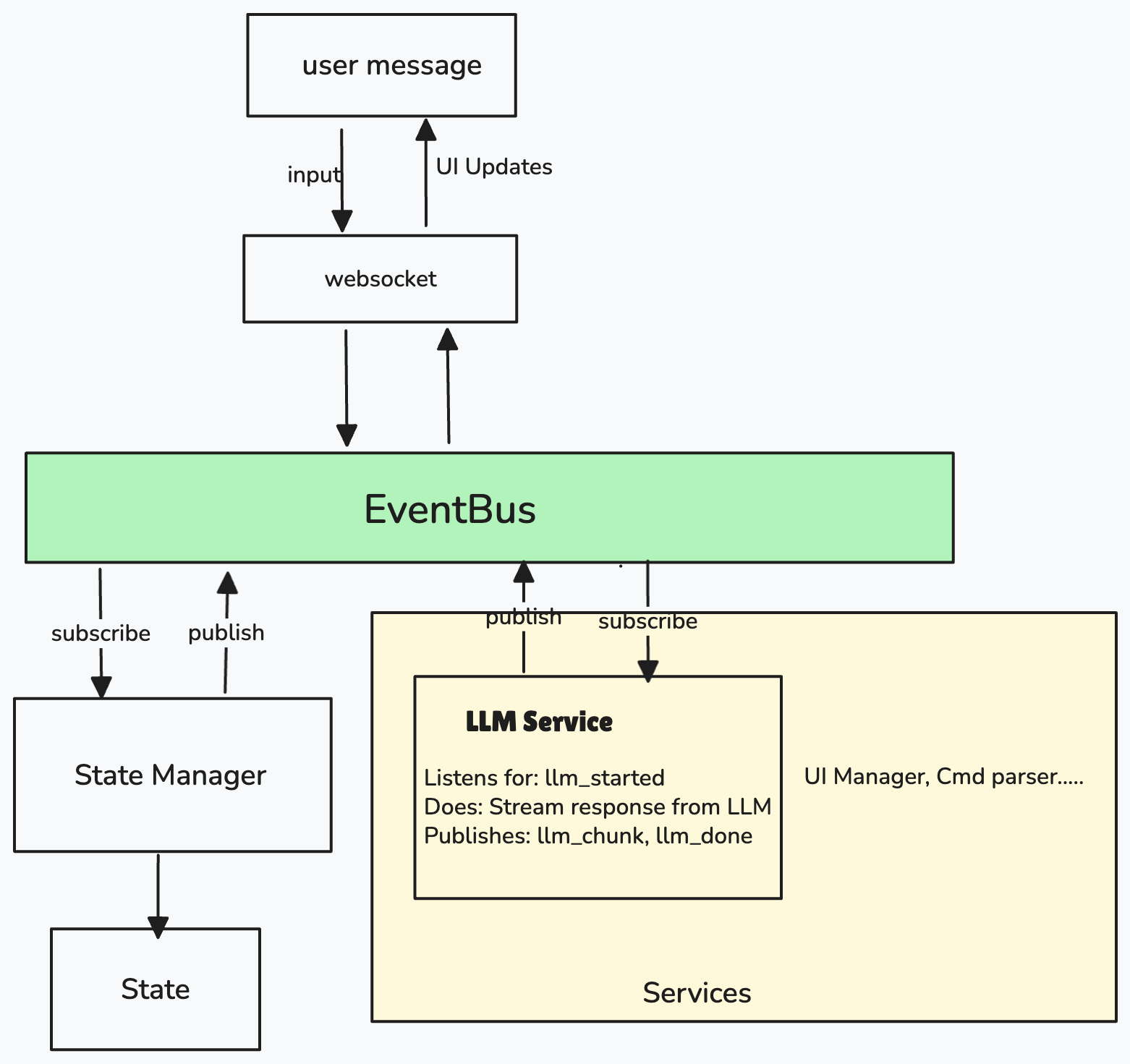
Component 1: EventBus - The Central Hub
Imagine your LLM is streaming output , you want to stop the streaming mid way . How do you tell that? You need to run concurrent tasks you need a queue
Need: Multiple async tasks running at the same time need a way to send messages to each other without blocking or using messy global variables.
Solution: A shared queue (EventBus) where anyone can post messages and anyone can read messages.
How it works:
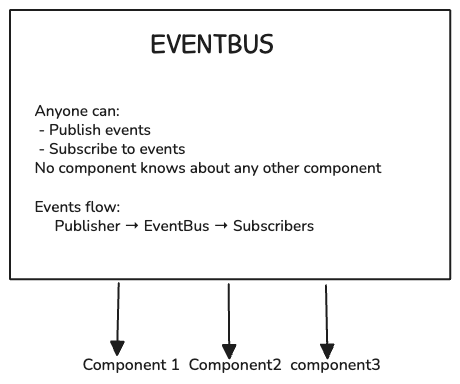
Key Points:
- Publishers don't know who's listening
- Subscribers don't know who's publishing
- Multiple subscribers can listen to same event
- Add new subscribers without changing publishers
Real example: When user sends message:
- WebSocket publishes
UserMessageEvent - EventBus broadcasts to: StateManager, Logger, Metrics
- Each subscriber reacts independently
Component 2: StateManager - The Single Source of Truth
We have a Eventbus and message are flowing . We need a state to remember
- Conversation history
- Whether we're streaming
- Messages that arrived while busy (Queue)
- Code waiting for human approval
The Problem: Who Can Touch State?
if every service can update the state , we will have race conditions when events happens at the same time like
Thread 1: state["messages"][-1]["content"] += "Hello"
Thread 2: state["pending_command"] = {"code": "2+2"}
↑
Both trying to modify state at once!
- Race conditions - multiple services touching state
- hard to debug - who changed is_streaming to false?
- no single place to look to understand state changes
- services are tightly coupled with state structure
Need: Track current system state and make decisions.
Solution: A State Manager that knows everything about current state.
What goes in:
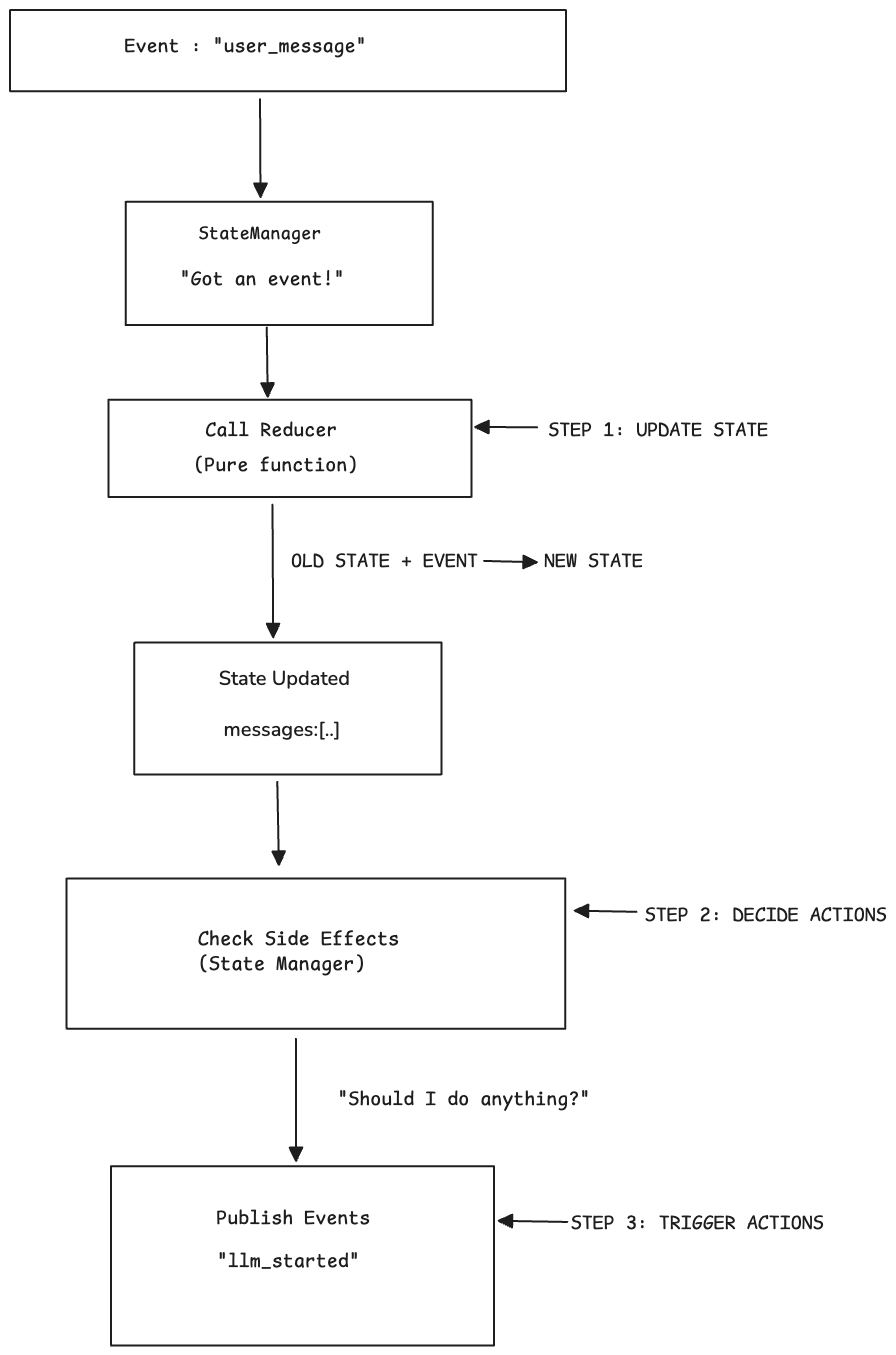
How it works:
- Services publish events (they never touch state)
- StateManager listens to all events
- StateManager updates state (with lock for safety)
- StateManager checks if updates trigger side effects (like starting LLM)
- StateManager publishes new events for side effects
Key Points:
- ✓ Single source of truth (only StateManager modifies state)
- ✓ Atomic updates (lock prevents race conditions)
- ✓ Centralized logic (all state transitions in one place)
- ✓ Services stay simple (they just publish/subscribe events)
Component 3: WebSocket - The UI Bridge
Need: Connect browser UI to backend system.
Solution: Bidirectional channel that translates between UI and events.
What goes in and out:
┌──────────────────────────┐
│ From Browser │
│ • User types message │
│ • User clicks Approve │
│ • User clicks Stop │
└────────┬─────────────────┘
│
▼
┌─────────────────────────────────┐
│ WebSocket │
│ │
│ Translates to events: │
│ • UserMessageEvent │
│ • ApprovalEvent │
│ • InterruptEvent │
└────────┬────────────────────────┘
│
▼
┌──────────────────────────┐
│ To Browser │
│ • State updates │
│ • "AI is thinking..." │
│ • Messages │
└──────────────────────────┘
Key Points:
- Listens to ALL events from EventBus
- Broadcasts every state change to UI
- Frontend sees: "🟢 Connected" → "⏳ Processing..." → "✅ Done"
Component 4: Services
When llm_started appears in EventBus, someone needs to actually call the LLM API. When chunks arrive, someone needs to parse them for function calls. We need specialized workers that do the actual work.
What Services Are: Independent async tasks that:
- Subscribe to specific events they care about
- Do specialized work (call APIs, parse text, execute code)
- Publish new events with results
No service calls another service directly. They communicate only through EventBus. This loose coupling makes the system flexible and maintainable.
LLMService - The AI Engine
Need: Call LLM API and stream responses.
Solution: Service that listens for "start AI" events and publishes results.
What goes in and out:
┌──────────────────────────┐
│ Input │
│ LLMResponseStartedEvent │
└────────┬─────────────────┘
│
▼
┌─────────────────────────────────┐
│ LLMService │
│ │
│ 1. Get conversation messages │
│ 2. Call OpenAI API (async) │
│ 3. Wait for response │
└────────┬────────────────────────┘
│
▼
┌──────────────────────────┐
│ Output │
│ LLMCompletedEvent │
│ (with AI response) │
└──────────────────────────┘
Key Points:
- Async OpenAI calls: Doesn't freeze the system
- While waiting for OpenAI, EventBus still processes other events
- Can detect interrupt signals during processing
- Only job: Call AI and publish result
Why async matters:
- Synchronous: System frozen for 10 seconds → queuing doesn't work
- Asynchronous: System responsive during 10 seconds → queuing works
CommandParser - The Function Call Detector
Need: Detect when AI wants to run code.
Solution: Parse AI responses for function call syntax.
What goes in and out:
┌──────────────────────────┐
│ Input │
│ LLMCompletedEvent │
│ (AI response text) │
└────────┬─────────────────┘
│
▼
┌─────────────────────────────────┐
│ CommandParser │
│ │
│ Check for: │
│ <function_calls> │
│ <invoke name="eval"> │
│ <parameter>...</parameter> │
│ </invoke> │
│ </function_calls> │
└────────┬────────────────────────┘
│
▼
┌──────────────────────────┐
│ Output │
│ CommandRequestedEvent │
│ (if function call found)│
└──────────────────────────┘
Key Points:
- Only listens to
LLMCompletedEvent - Parses XML format for function calls
- Publishes
CommandRequestedEventif found - Frontend shows approval modal
CommandExecutor - The Action Taker
Need: Execute approved commands safely.
Solution: Wait for approval, then run the code.
What goes in and out:
┌──────────────────────────┐
│ Input │
│ CommandStartedEvent │
│ (after user approval) │
└────────┬─────────────────┘
│
▼
┌─────────────────────────────────┐
│ CommandExecutor │
│ │
│ 1. Run the code │
│ 2. Capture result or error │
│ 3. Can be interrupted │
└────────┬────────────────────────┘
│
▼
┌──────────────────────────┐
│ Output │
│ CommandCompletedEvent │
│ (with result) │
│ OR │
│ CommandFailedEvent │
│ (with error) │
└──────────────────────────┘
Key Points:
- Waits for user approval before running
- Can be interrupted mid-execution
- Results go back to AI for next response
How Components Work Together
Here's the complete system:
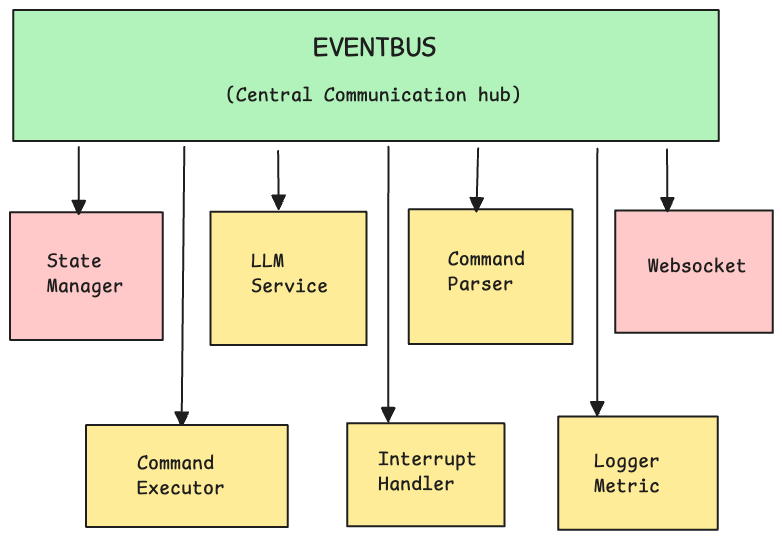
All connected through EventBus - no direct communication
The flow:
- User action → WebSocket → Publishes event
- EventBus → Broadcasts to all subscribers
- Each service reacts independently
- State updates → WebSocket → UI updates
Why this works:
- Decoupled: Change one component, others unaffected
- Extensible: Add new features by adding subscribers
- Testable: Mock EventBus, test components in isolation
- Concurrent: All services run in parallel
Solving Pattern 2: Message Queuing (Detailed Flow)
Let's trace exactly how message queuing works with this architecture.
Scenario: User sends follow-up question while AI is processing
Step 1: Initial message
┌────────┐
│ User │ "Analyze Q4 sales"
└───┬────┘
│ UserMessageEvent
▼
┌────────────────┐
│ StateManager │ is_streaming = false → Start AI
└────┬───────────┘
│ LLMResponseStartedEvent
▼
┌─────────────┐
│ LLMService │ Calling OpenAI... (takes 15 seconds)
└─────────────┘
Step 2: Follow-up message (5 seconds later)
┌────────┐
│ User │ "Just top 3 regions"
└───┬────┘
│ UserMessageEvent
▼
┌────────────────┐
│ StateManager │ is_streaming = TRUE → QUEUE IT
│ │ queued_messages = ["Just top 3 regions"]
└────────────────┘
│
▼
┌──────────────┐
│ WebSocket │ "✓ Message queued"
└──────────────┘
Step 3: AI finishes first request
┌─────────────┐
│ LLMService │ OpenAI returns result
└────┬────────┘
│ LLMResponseCompletedEvent
▼
┌────────────────┐
│ StateManager │ is_streaming = false
│ │ Check queue → Found message!
└────┬───────────┘
│ Publish queued message
▼
┌─────────────┐
│ LLMService │ Process "Just top 3 regions"
└─────────────┘
Result: User gets both analyses without repeating
Why traditional architecture fails here:
Traditional approach:
┌────────┐
│ User │ "Analyze Q4"
└───┬────┘
│
▼
┌──────────────┐
│ Agent │ Processes... [BLOCKS for 15 seconds]
└──────────────┘
│
│ [User sends "Just top 3"]
│ → Message arrives while Agent is blocked
│ → No one listening
│ → MESSAGE LOST
▼
User: "Why didn't it work?"
Event-driven solves it:
- LLMService is busy, but EventBus is not
- StateManager is listening
- StateManager makes decision: queue the message
- After LLM finishes, StateManager processes queue
The magic: EventBus allows concurrent listening even when services are busy.
Solving Pattern 6 :Repeatable Workflows - Slash Commands
Let's see how custom workflows triggered by commands works with this architecture:
How it works:
User: "/pr-review"
↓
CommandParser detects slash command
↓
Publishes: WorkflowRequestedEvent(workflow="pr-review", args=[...])
↓
WorkflowService receives event
↓
Executes workflow steps:
1. Publishes: ToolExecutionEvent (run git diff)
2. Publishes: UserMessageEvent (AI analyzes code)
3. Publishes: FormatResultsEvent (structure output)
↓
Each step flows through EventBus
↓
Results stream back to UI in real-time
What you'd add:
- WorkflowService: Subscribes to
WorkflowRequestedEvent, orchestrates multi-step operations - WorkflowRegistry: Stores workflow definitions (user or system-defined)
- CommandParser enhancement: Detect
/prefix, parse workflow name and arguments
Real example:
class WorkflowService: def __init__(self, event_bus): event_bus.subscribe("workflow_requested", self.execute_workflow) self.workflows = { "pr-review": PRReviewWorkflow(), "add-ticket": JiraTicketWorkflow(), "debug-error": DebugWorkflow() } async def execute_workflow(self, event): workflow = self.workflows[event.workflow_name] async for step in workflow.steps(): # Each step publishes events through EventBus await step.execute(event_bus) # Can be interrupted at any step # Progress streamed to UI automatically
Why it fits perfectly:
- Workflows = orchestrated sequences of events
- Can trigger LLM calls, tool executions, approvals - all through EventBus
- Can be interrupted mid-workflow (Pattern 3)
- Results stream in real-time (Pattern 1)
- Zero coupling - workflows just publish/subscribe events
Production use: Claude Code uses this exact pattern for /pr-review, /generate-tests, custom workflows. Developers save hours by encoding repetitive tasks once.
Key Architectural Decisions Explained
Decision 1: Why Pure Reducers in StateManager?
What it means: State changes follow this pattern:
Input: Current state + Event
Output: New state (never modify current state)
Why it matters:
- Predictable: Same input always produces same output
- Testable: No need to mock anything
- Debuggable: Can log before/after state
- Replayable: Can recreate any state by replaying events
Real example:
Current state: {messages: ["Hello"], is_streaming: false}
Event: UserMessageEvent("How are you?")
Reducer returns NEW state:
{messages: ["Hello", "How are you?"], is_streaming: false}
Original state unchanged - predictable!
Decision 2: Service Independence Through EventBus
This is the biggest architectural decision.
Traditional approach (tightly coupled):
LLMService → directly calls → WebSocket
→ directly calls → Logger
→ directly calls → Metrics
Want to add audit logging?
→ Modify LLMService code to call AuditLogger
→ Modify tests to mock AuditLogger
→ Existing features might break
→ Every new feature requires code changes
Event-driven approach (loosely coupled):
LLMService → publishes LLMCompletedEvent → EventBus
EventBus → broadcasts to all subscribers:
→ WebSocket (shows result to user)
→ Logger (logs the event)
→ Metrics (tracks usage)
Want to add audit logging?
→ Create AuditLogger class
→ Subscribe to events in EventBus
Real example - Adding compliance logging:
# Before EventBus (modify existing code): # 1. Open llm_service.py # 2. Add: compliance_logger.log(response) # 3. Update tests # 4. Hope nothing broke # With EventBus (add new subscriber): class ComplianceLogger: def __init__(self, event_bus): event_bus.subscribe("llm_response_completed", self.log) async def log(self, event): # Log to compliance system await compliance_db.save(event) # That's it! No changes to LLMService, StateManager, or tests
Why this matters for production:
When your AI agent goes to production, you'll need:
- 📊 Metrics: Track API costs, response times, error rates
- 📝 Audit logs: Compliance requires logging all AI interactions
- ⚠️ Error tracking: Send failures to Sentry/DataDog
- 📈 Analytics: Understand user patterns
- 🔐 Security: Monitor for suspicious activity
With EventBus: Add each feature by creating a new subscriber
Without EventBus: Modify core agent code for each feature (hours per feature, risk breaking existing functionality)
The flexibility: You can add as many services as needed in the future without touching existing code. This is what makes the architecture production-ready.
Decision 3: Why Async (Non-Blocking I/O)?
The problem: OpenAI API calls take 5-10 seconds. If we wait synchronously, the entire system freezes.
Synchronous approach (blocking):
User sends message
↓
StateManager calls OpenAI
↓
[WAIT 10 SECONDS - System completely frozen]
↓
- Can't process new user messages
- Can't queue messages
- Can't send UI updates
- EventBus can't process any events
↓
Response arrives
Asynchronous approach (non-blocking):
User sends message
↓
StateManager starts OpenAI call with 'await'
↓
[OpenAI processing - System remains responsive]
↓
- EventBus continues processing events
- New user messages get queued
- UI updates still work
- Other services keep running
↓
Response arrives when ready
Why it's critical:
This is what makes message queuing work. When a user sends a second message while the AI is processing the first one:
- LLMService is waiting for OpenAI (10 seconds)
- Because we use async: StateManager is still listening for events
- New UserMessageEvent arrives
- StateManager queues it immediately
- When OpenAI finishes, queued message gets processed
Without async: StateManager would be frozen, second message would be lost or error out.
Note: Async is about non-blocking I/O, not streaming. In Phase 1, we get the full response at once (non-streaming). In Phase 2, we'll add character-by-character streaming, but we'll still use async for the same reason - keeping the system responsive.
Decision 4: Pure Reducers for State Updates
Production Considerations
What This Architecture Enables
Currently working:
- Message queuing during AI processing
- Real-time UI status updates
- Non-blocking concurrent operations
Future releases:
- True streaming (character-by-character)
- Interrupt handling
- Function call parsing
- Approval flows
- Command execution
- Metrics, error , audit logging
Beyond Real-Time: Background Tasks
Pattern 5 (long-running tasks with notifications) fits naturally into this architecture:
What you'd add:
- BackgroundTaskService: Subscribes to
StartBackgroundTaskEvent, queues tasks in Redis/Celery - NotificationService: Subscribes to
TaskCompleteEvent, sends browser notification (if user online) or email (if offline) - Task persistence: Database stores task status so users can reconnect later
The beauty: Zero changes to existing EventBus, StateManager, or LLMService. Just add new subscribers. A CEO can request a 20-minute analysis, close their browser for a meeting, and get an email when it's done. The event-driven foundation makes this trivial to implement.
Conclusion
Event-driven architecture solves real production problems:
- Streaming responses: Users see AI thinking in real-time
- Message queuing: Users don't lose input during processing
- Interrupts: Users control their time
- Function calls: AI can take actions with approval
- Background tasks: Long operations run independently with notifications
- Repeatable workflows: Complex multi-step operations triggered by simple commands
- Extensibility: Add features without breaking existing code
The key patterns:
Loose Coupling:
- No service directly calls another
- All communication through events
- Services can be added/removed without breaking others
Concurrent Execution:
- All services run as independent async tasks
- Multiple things happen simultaneously (parsing while updating state while showing UI)
Single Responsibility:
- Each component has one clear job
- Easy to understand, test, and modify in isolation
Coordination Without Central Control:
- No "master controller" orchestrating everything
- System self-organizes through event reactions
- StateManager triggers side effects, but services decide how to react
Questions? Your Use Cases?
I am not trying to build something academic - It has to be an architecture that production AI agents can you with real user traffic.
I'd love to hear:
Have you built AI agents?
- What patterns did you struggle with?
- How did you handle concurrent user actions?
- What would you architect differently?
Have real production requirements?
- Multiple users editing same conversation?
- Need to audit every AI action?
- Integration with existing systems?
- Compliance/security concerns?
Drop a comment or open an issue on GitHub.
Code: github.com/sandipan1/event-driven-agent